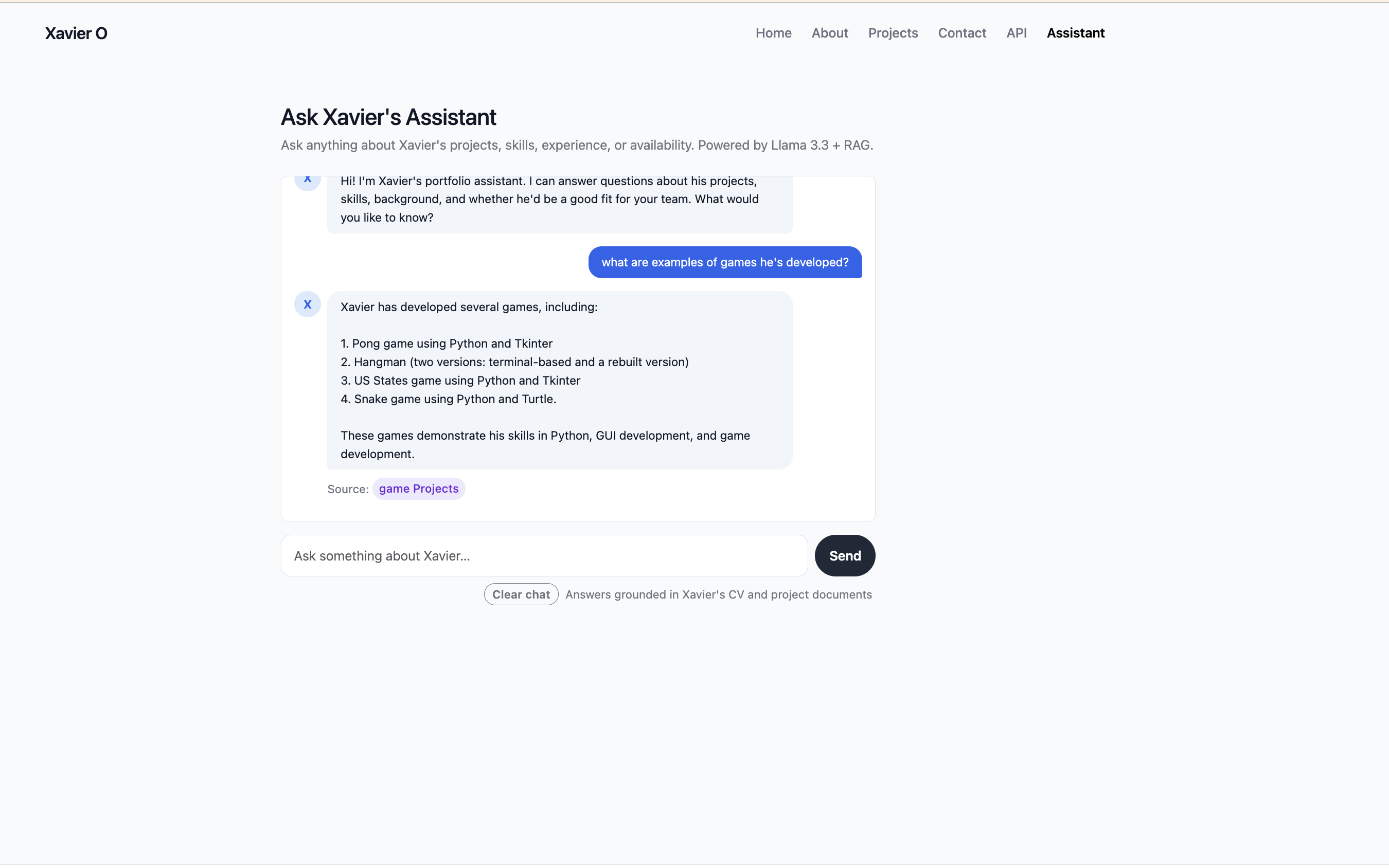
AI Portfolio Assistant
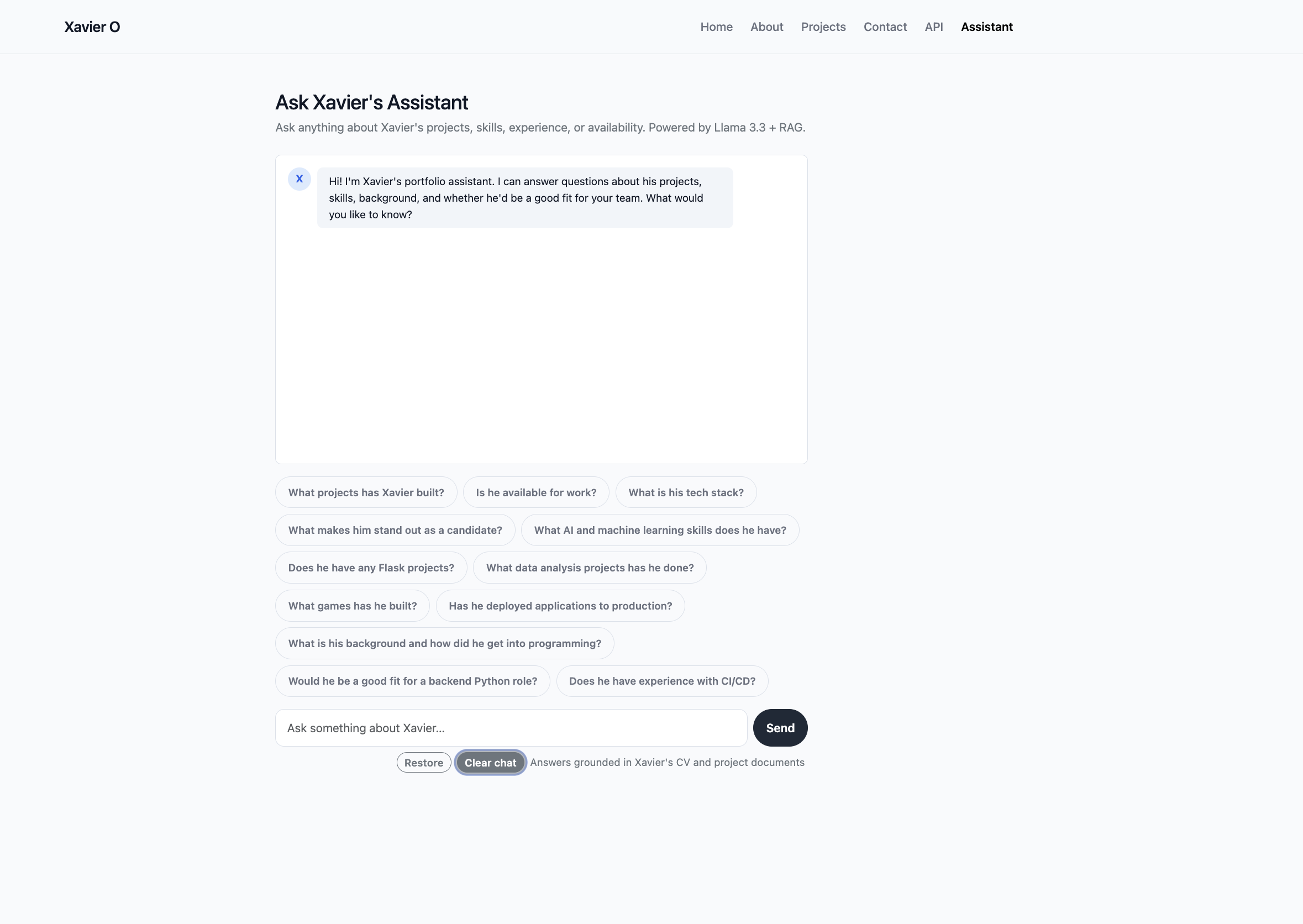
The assistant lives at /assistant and lets anyone have a real conversation about my background. It knows about my CV, my skills, my personal story, and every single project in my portfolio. Ask it whether I'd be a good fit for a backend Python role, what games I've built, or whether I have CI/CD experience — it retrieves the relevant information from my actual documents and gives you a grounded, cited answer.
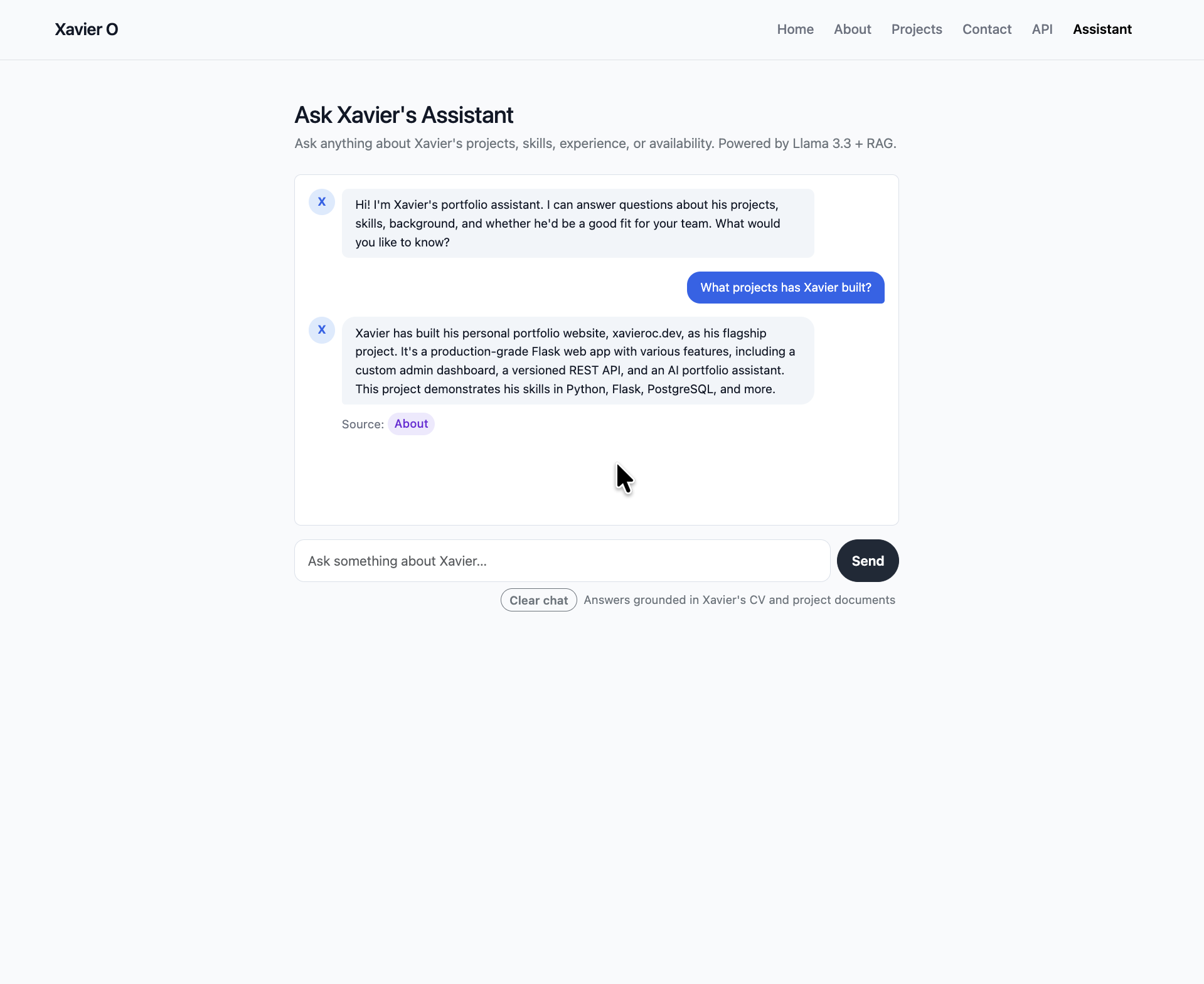
The architecture is a full RAG pipeline built as a Flask blueprint. At startup, it indexes two types of knowledge: static Markdown files (my CV, skills breakdown, and personal narrative) and live project records queried straight from the PostgreSQL portfolio database. That second part was a deliberate design choice — it means the assistant always reflects the current state of my portfolio. Every time I add or update a project through the admin dashboard, it's automatically available to the assistant on the next deploy, with no manual knowledge base maintenance required.
Embeddings run entirely locally using sentence-transformers/all-MiniLM-L6-v2 — no API key, no cost, no latency from an external call. ChromaDB stores the vector index on disk so it only rebuilds when needed. At query time, the four most semantically relevant chunks are retrieved and injected into the prompt alongside the conversation history before the request goes to Llama 3.3 70B on Groq.
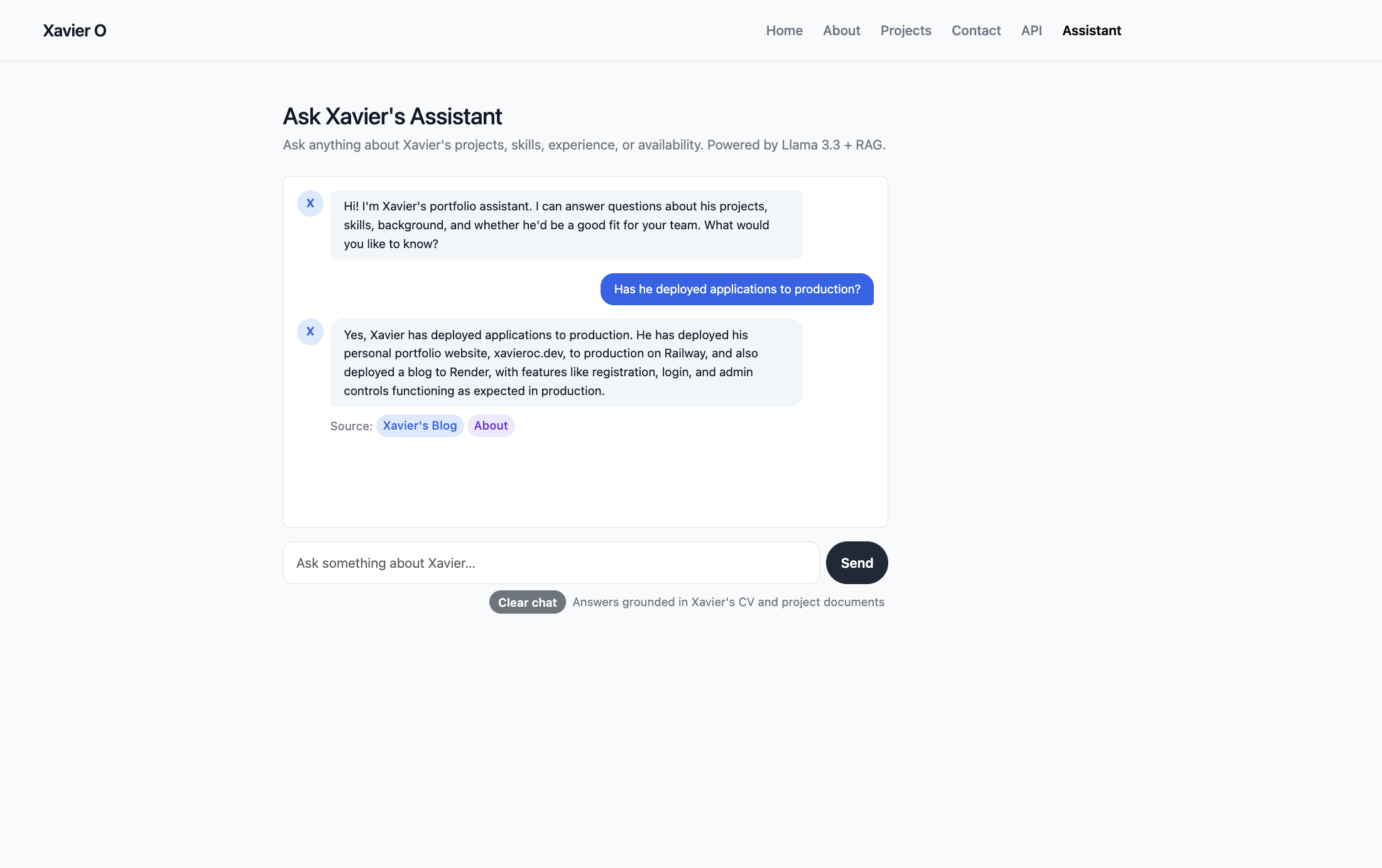
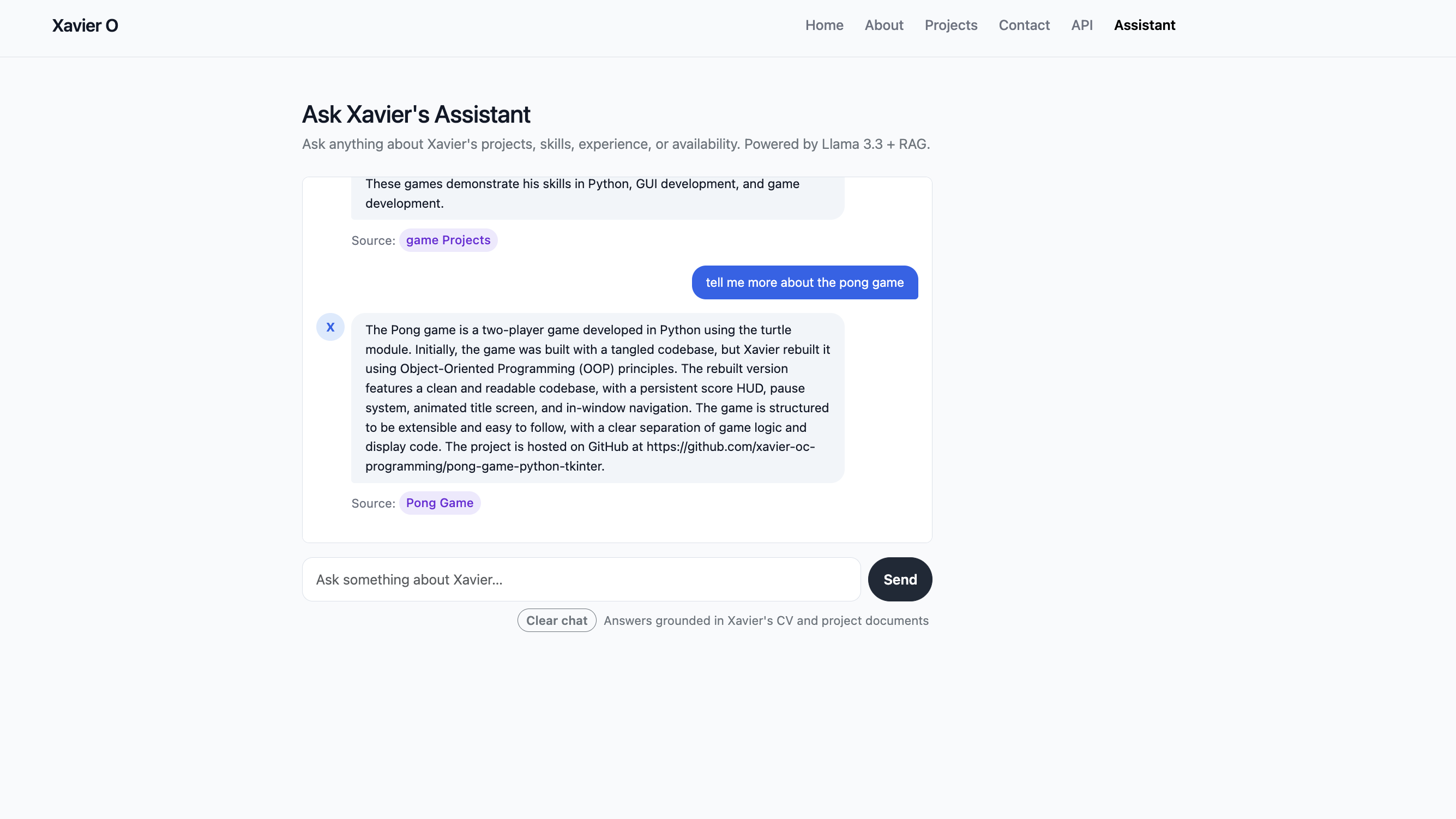
One of the details I'm most pleased with is the smart source citations. When the assistant answers, it doesn't just say "source: projects" — it links somewhere specific. A question about a particular project links straight to that project's detail page. A question about Flask links to /projects?tag=flask. A question about data work links to /projects/data. A broad question falls back to /projects. This required building a tag frequency system across retrieved chunks and a GENERIC_TAGS exclusion list to stop tags like "python" or "programming" from winning over meaningful ones like "flask" or "machine-learning".
The chat UI is built with Bootstrap 5 — no page reloads, everything via fetch(). It renders Markdown, persists the full conversation in localStorage with a clear and restore flow, and ships with twelve starter prompts covering the range of questions a recruiter might actually ask. Rate limiting is enforced per IP at 15 requests per minute and 1,500 per day using flask-limiter, with context-aware error messages depending on which limit was hit.
Quick Facts
Overview
Problem
My portfolio was a static site — a recruiter landing on it had to click through every project page manually to work out whether I'd be a good fit. There was no way to ask a direct question. Generic AI chatbots didn't know anything about me specifically, and if you asked one to describe my projects it would just hallucinate plausible-sounding nonsense. I needed something that could have a real, specific, honest conversation about my work on my behalf.
Solution
I built a RAG pipeline so the assistant only ever answers from verified source documents — it cannot invent information it wasn't given. Instead of a static knowledge file for projects, I wired it directly to the portfolio database so it always reflects live data. Source citations link to the actual relevant pages on the site, so the assistant becomes a navigation layer as much as a Q&A tool — it answers the question and then hands the visitor off to the right place to learn more.
Challenges
The first version used Gemini 2.5 Flash, which hit a 20 request/day free tier limit — completely unworkable for a public portfolio tool. I switched to Groq's free tier (Llama 3.3 70B, 14,400 requests/day) which was the right call.
Getting the LangChain stack to play nicely took real debugging. langchain-groq 1.1.2 requires langchain-core>=1.2.8, which was incompatible with the langchain 0.3.x stack I had installed. I had to upgrade the entire chain of packages in lockstep. Then chromadb 0.5.23 turned out to be incompatible with langchain-chroma 1.1.0, which needs chromadb>=1.3.5 — another version bump needed.
The smart source links went through two iterations. The first approach required a tag to appear in every retrieved project chunk — but if one slightly off-topic chunk got pulled in, the intersection would drop to empty and fall back to /projects. I switched to frequency-based selection instead: find the most common non-generic tag across all retrieved chunks and use that. That fixed it — a tag now "wins" when most of the retrieved chunks are of that respective tag, even if one stray chunk doesn't have it.
Results / Metrics
The assistant is live at xavieroc.dev/assistant. It answers questions about all my portfolio projects with accurate, clickable citations. It routes visitors to filtered project views by tag or category. It runs entirely on free-tier infrastructure — no ongoing API cost. And because the knowledge base is backed by the live database, it stays current automatically with every deploy. It's the part of this portfolio I'd most want a recruiter to see.
Screenshots
Click to enlarge.
Click to enlarge.
Videos
No videos available yet.