AWS Lambda & Amazon Bedrock: Benchmarking TF-IDF, LSTM, and Zero-Shot LLM Sentiment Analysis
For this project I built a complete sentiment analysis pipeline from scratch, training and benchmarking three approaches on the IMDb Movie Reviews dataset — 50,000 labelled reviews split evenly between positive and negative. The goal was not just to get a working model, but to rigorously compare classical NLP, deep learning, and foundation model inference, and then deploy the result as a production-grade serverless API on AWS.
I trained two models locally: a TF-IDF + Logistic Regression baseline using scikit-learn, and a Keras LSTM sequence model using TensorFlow. Both were evaluated on the same 25,000-review held-out test set across accuracy, precision, recall, F1, AUC, and confidence calibration. I also integrated Amazon Bedrock to call Claude Haiku 4.5 for zero-shot inference, gaining hands-on experience with the Bedrock platform — navigating model access approval, IAM permissions, and the boto3 API in a real AWS environment.
The winning model (TF-IDF + Logistic Regression, F1 = 0.8945) was deployed as a containerised Flask app on AWS Lambda using Docker and ECR, fronted by an API Gateway HTTP API. I used the AWS Lambda Web Adapter to bridge Lambda's invocation model to Flask's standard HTTP server without writing any Lambda-specific handler code. The frontend includes a live demo with example reviews, a confidence bar, and a model comparison view.
Quick Facts
Overview
Problem
For this project I wanted to answer a question that comes up constantly in production ML: when is a trained model actually better than calling a foundation model API? I chose sentiment analysis on IMDb reviews as the benchmark task because it is well-understood, has a standard dataset and evaluation split, and is representative of real text classification workloads. I also wanted to go beyond just training models — I wanted to deploy something live and encounter the real constraints that come with serverless ML inference.
Solution
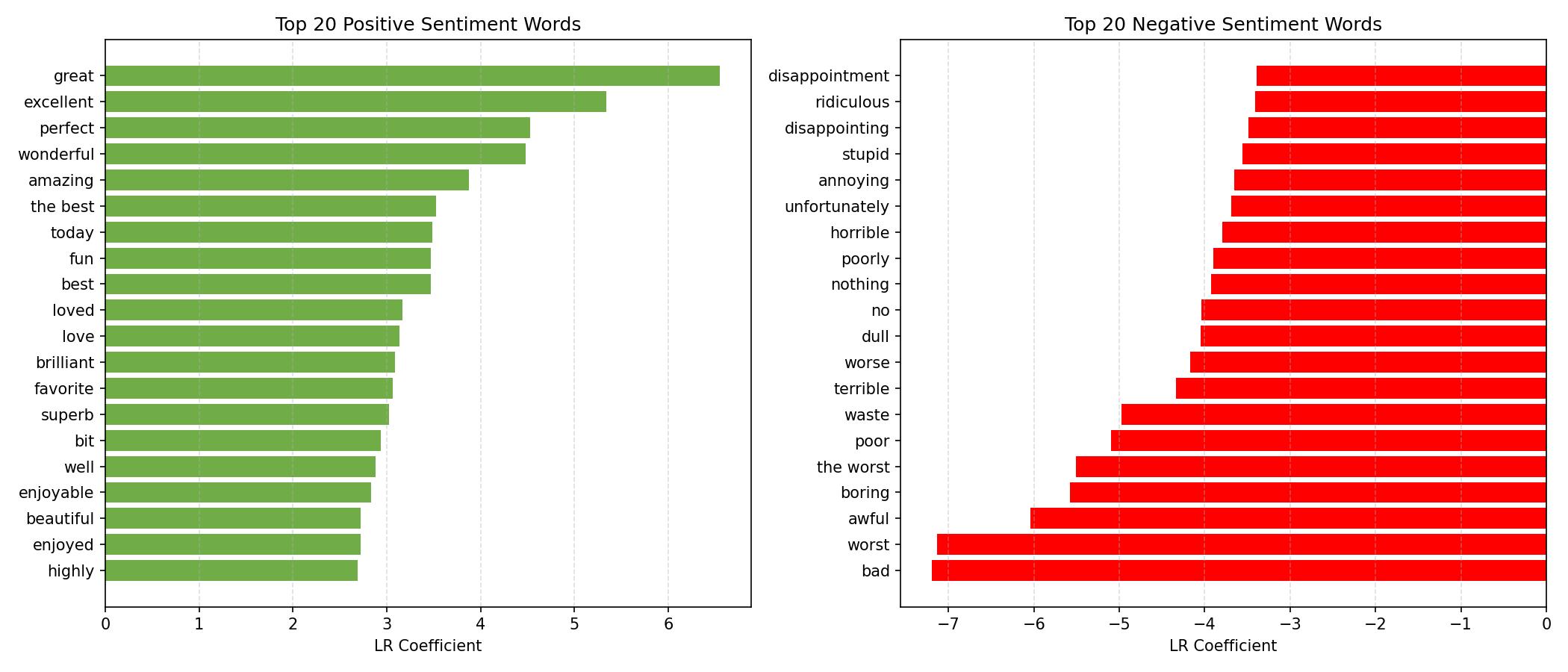
For this project I took a three-pronged approach. First, I trained a TF-IDF + Logistic Regression model — the classical NLP baseline — using scikit-learn with unigrams and bigrams to capture local negation patterns. Second, I trained a Keras LSTM with an embedding layer and dropout to learn sequential dependencies in the text. Third, I integrated Amazon Bedrock to run Claude Haiku 4.5 zero-shot on sample reviews, exploring the tradeoff between training cost, inference cost, and generalisation.
For deployment I initially investigated Zappa for Lambda zip packaging, but the deployment package exceeded Lambda's 250 MB limit due to TensorFlow's size. I moved to Docker container images on ECR, which support up to 10 GB — solving the size constraint. I then discovered that TensorFlow's ~50-second cold-start time exceeded API Gateway's hard 30-second timeout, so I excluded TensorFlow from the Lambda image and deployed the Logistic Regression model only. The LSTM is fully available in the local environment. I documented the alternative deployment paths (ONNX Runtime, TFLite, Provisioned Concurrency, ECS Fargate) and the tradeoffs behind each in the README.
Challenges
For this project the most significant technical challenge was the deployment of TensorFlow on AWS Lambda. I hit two compounding constraints: the package size limit (TensorFlow alone is ~500 MB, exceeding Lambda's 250 MB zip limit) and the cold-start timeout (TensorFlow takes ~50 seconds to initialise, exceeding API Gateway's hard 30-second limit). Solving the first by switching to Docker container images only revealed the second. The resolution was to deploy the Logistic Regression model only on Lambda — which loads in under a second — while keeping the full two-model comparison available locally.
A second challenge was the Amazon Bedrock integration. Access to Claude Haiku required submitting a use case form through the AWS console and waiting for propagation (~15 minutes). I also had to handle the model returning JSON wrapped in markdown code fences, which required a regex strip before parsing. Navigating real AWS IAM policies, Bedrock regional availability, and CloudTrail audit logs was a meaningful learning experience beyond just calling an API.
Results / Metrics
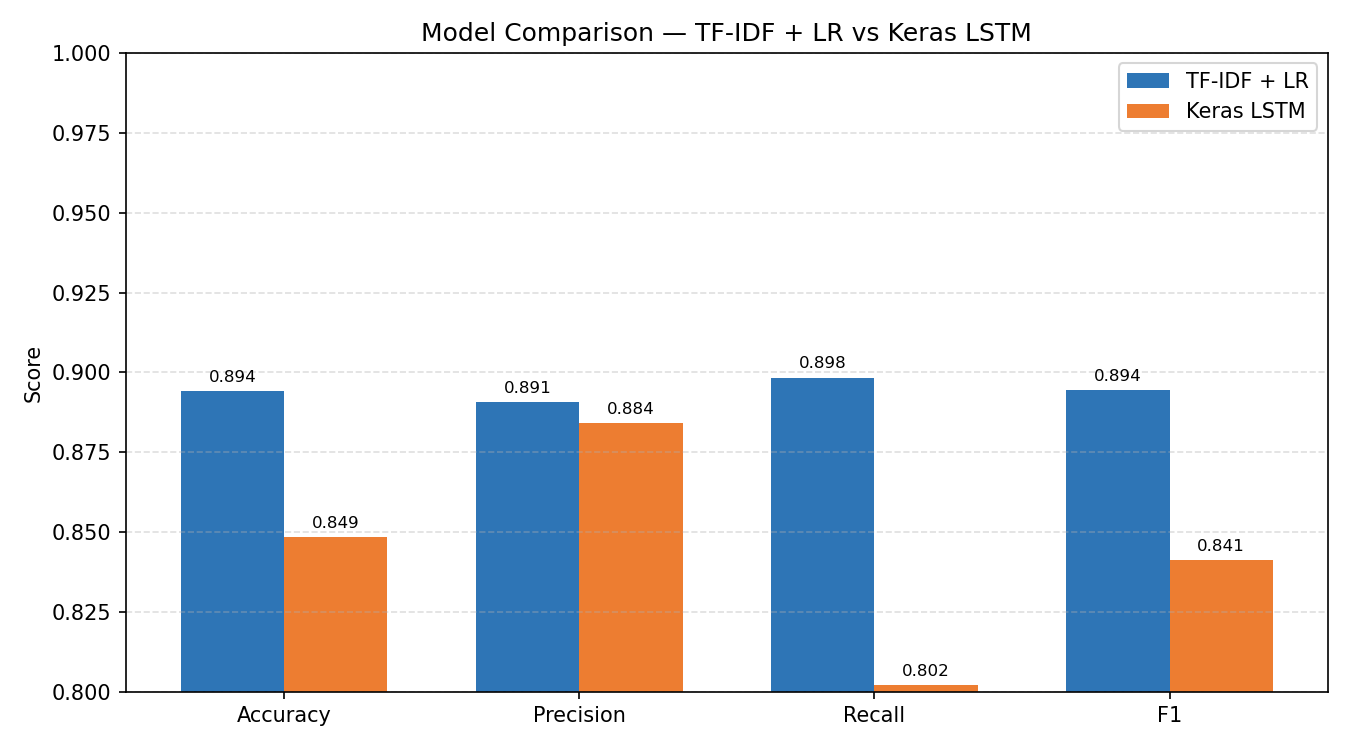
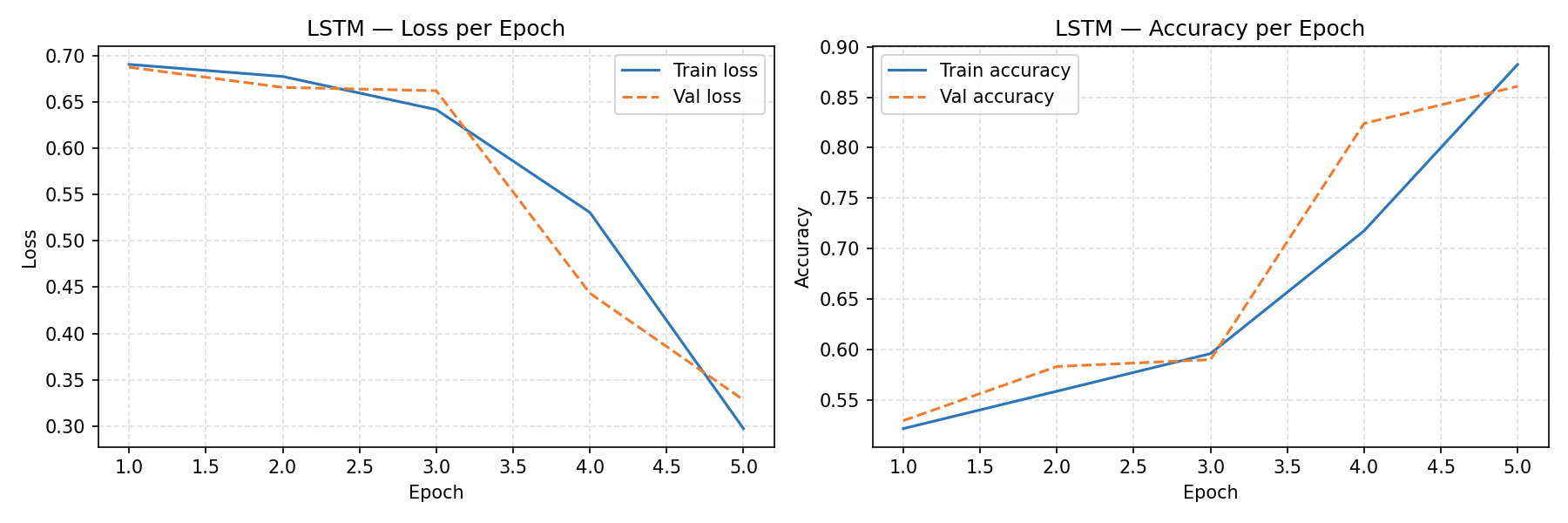
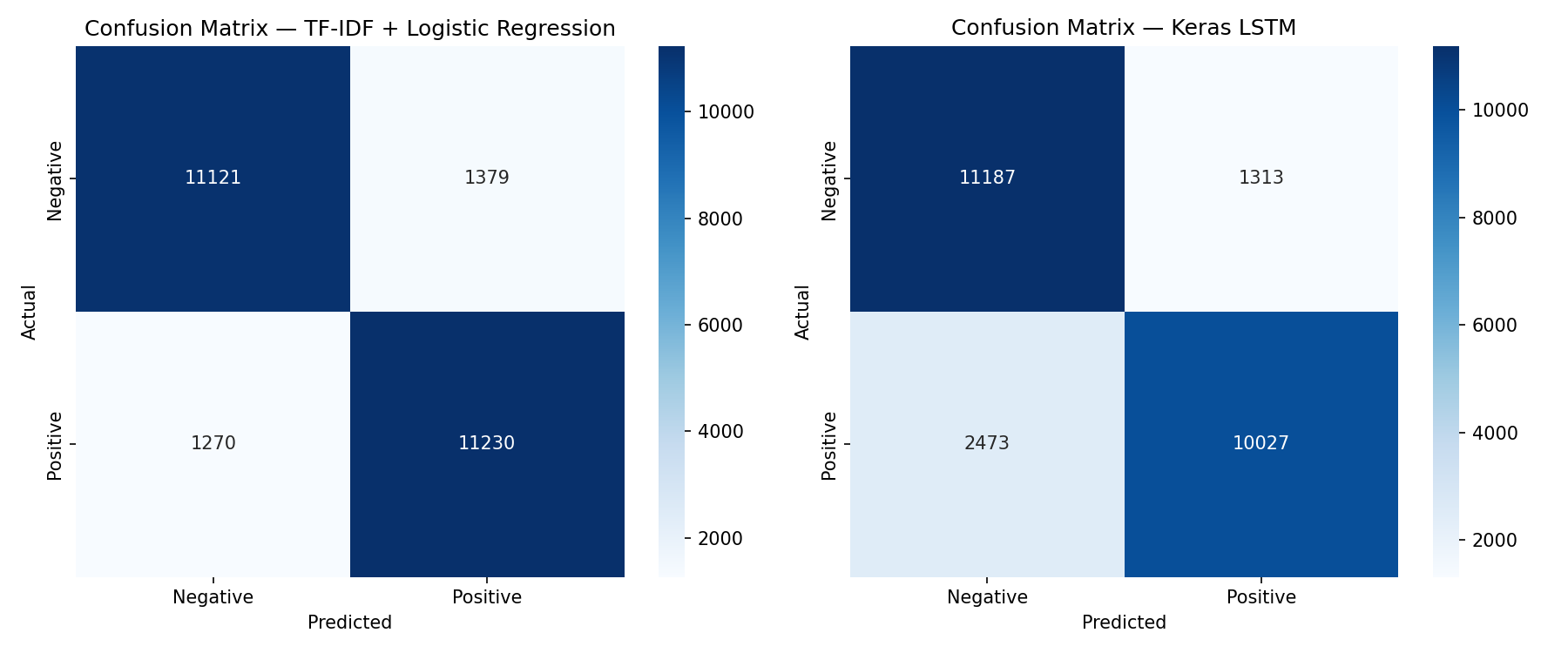
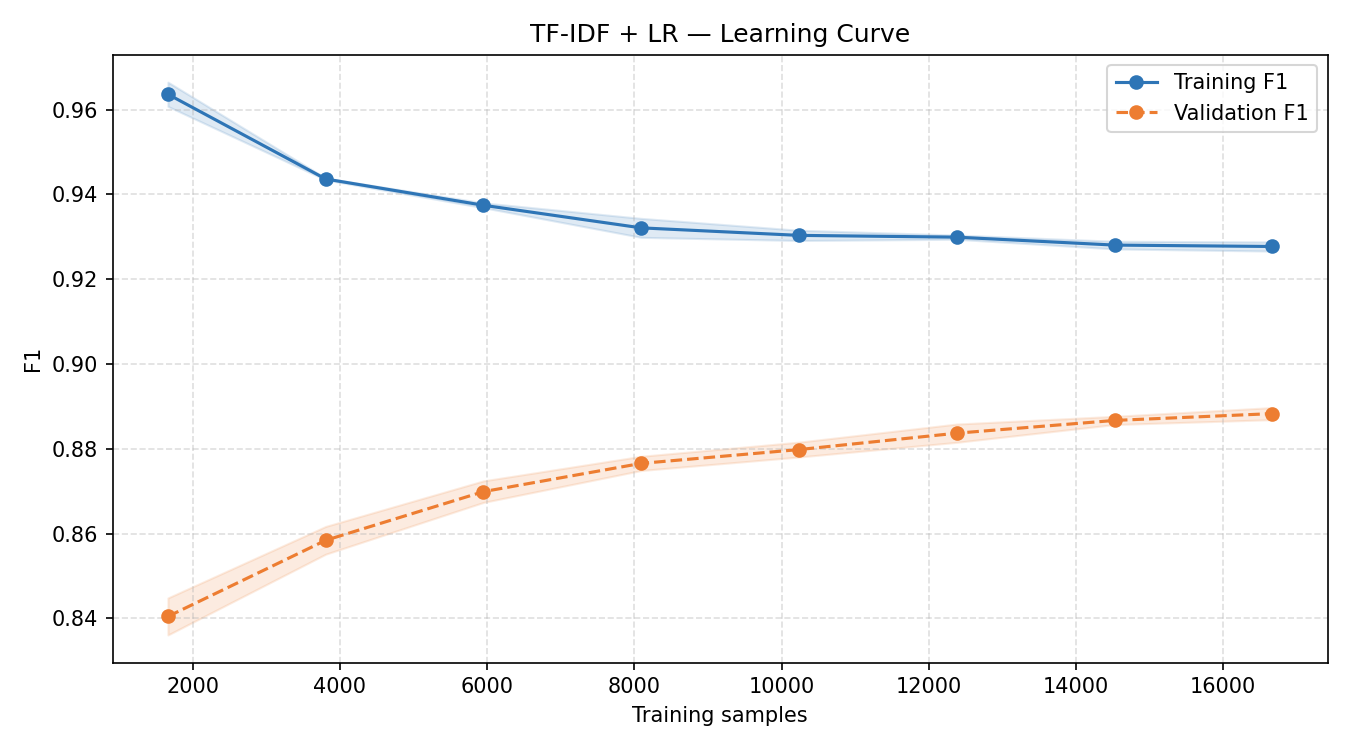
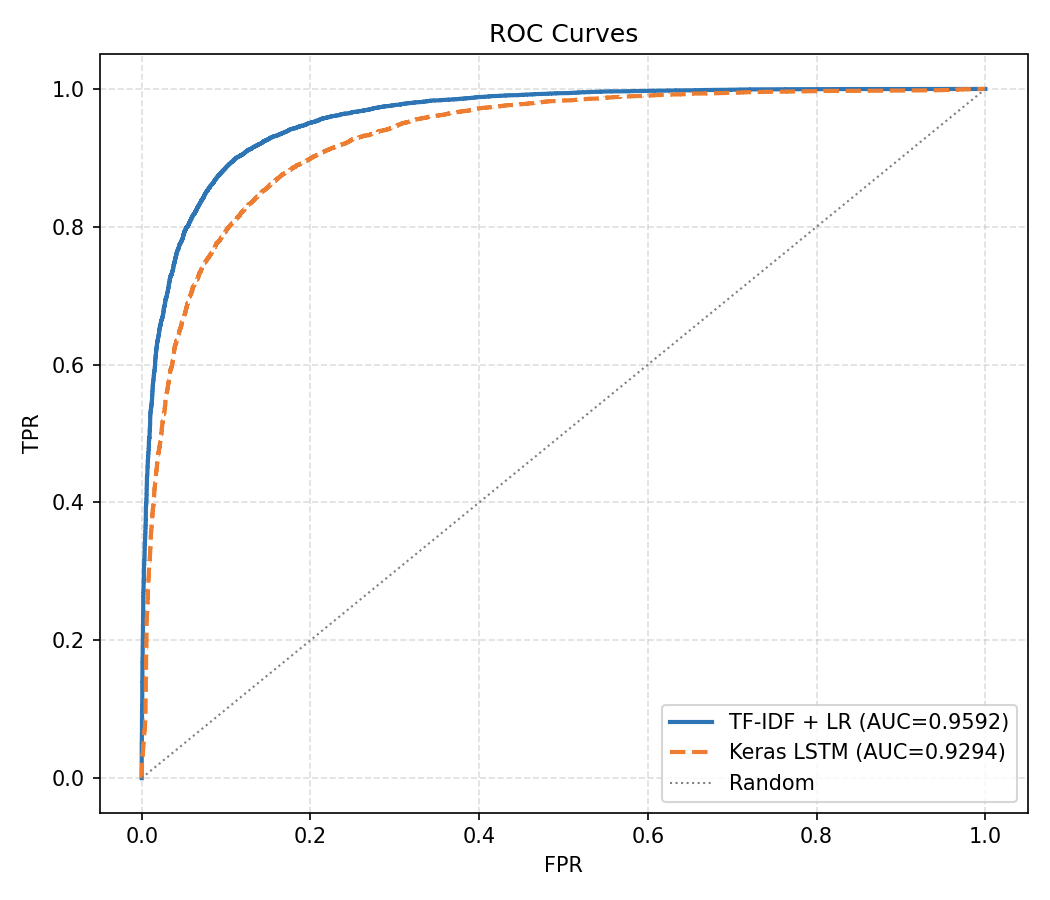
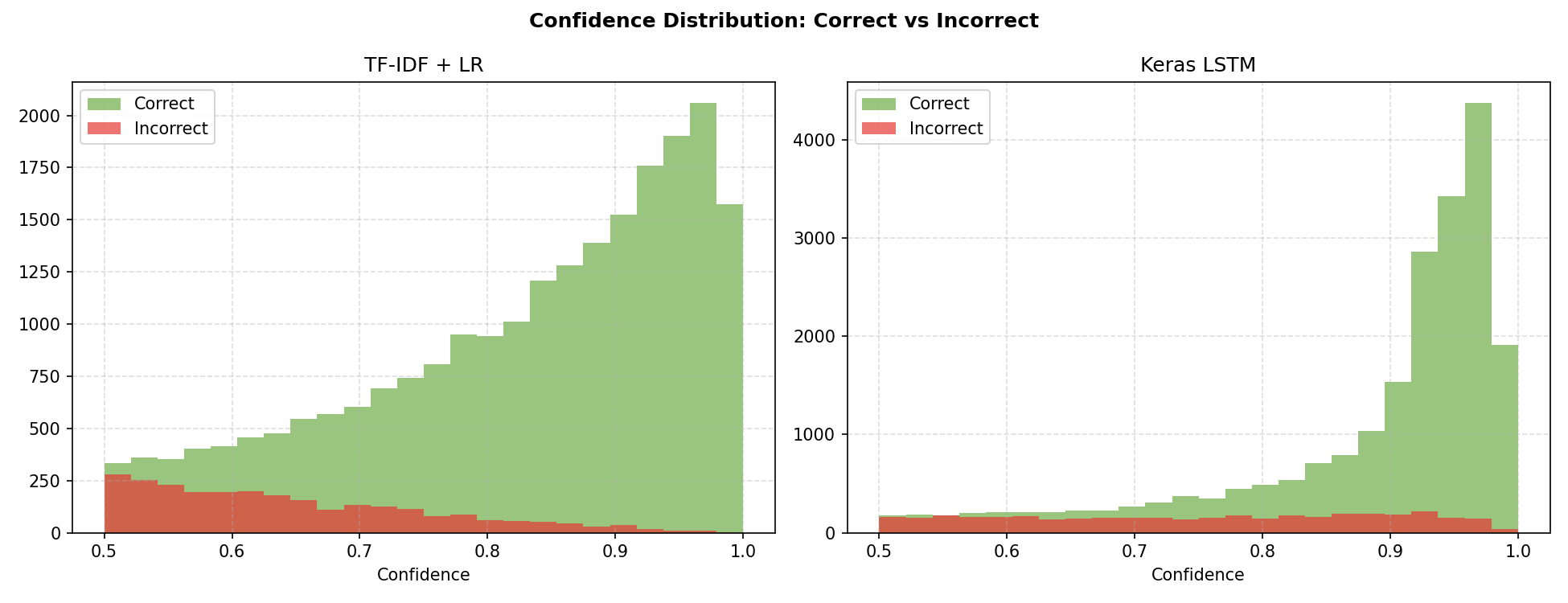
For this project the TF-IDF + Logistic Regression model outperformed the Keras LSTM on every metric: F1 of 0.8945 vs 0.8412, AUC of 0.9592 vs 0.9294, and recall of 0.898 vs 0.802. The LSTM misclassified nearly twice as many positive reviews as false negatives (2,473 vs 1,270). The LR learning curve showed validation F1 still rising at 16,500 training samples, suggesting further data would yield marginal gains. The LSTM's confidence distribution was notably more bimodal — it made very high-confidence predictions on most reviews, with incorrect predictions concentrated near 0.5, indicating reasonable calibration.
The live endpoint responds in under 100ms on warm Lambda instances. I produced seven visualisations covering model comparison, LSTM training curves, confusion matrices, top predictive words, LR learning curve, ROC curves, and confidence distribution — all with detailed analysis in the notebook. The project demonstrates the full ML engineering lifecycle: data loading, model training, evaluation, visualisation, API development, containerisation, and cloud deployment.
Screenshots
Click to enlarge.
Click to enlarge.