Spotify Musical Time Machine
Pick any date in history and this tool travels back in time through music. It scrapes that week's Billboard Hot 100, runs each song through a multi-stage fuzzy-matching pipeline against Spotify's catalogue, and creates a private playlist on your account. The OOP refactor splits the logic across BillboardScraper and SpotifyClient classes, with a central config module for all constants and credentials loaded from a .env file.
Quick Facts
Overview
Problem
Spotify doesn't have a built-in way to reconstruct what was actually popular on a specific date in history. If you want a playlist of the Billboard Hot 100 from the week you graduated or the month a particular album dropped, you'd have to look up the chart manually and search for every song one by one — which for 100 tracks is genuinely tedious. Billboard and Spotify don't share a direct integration, so there's no shortcut built into either platform. On top of that, Billboard artist strings are messy — they use different separators ("Featuring", "&", "feat.") depending on the era and chart position — and Spotify has its own catalogue quirks like remaster suffixes and compilation editions. A naive exact-match approach would miss a large chunk of the chart.
Solution
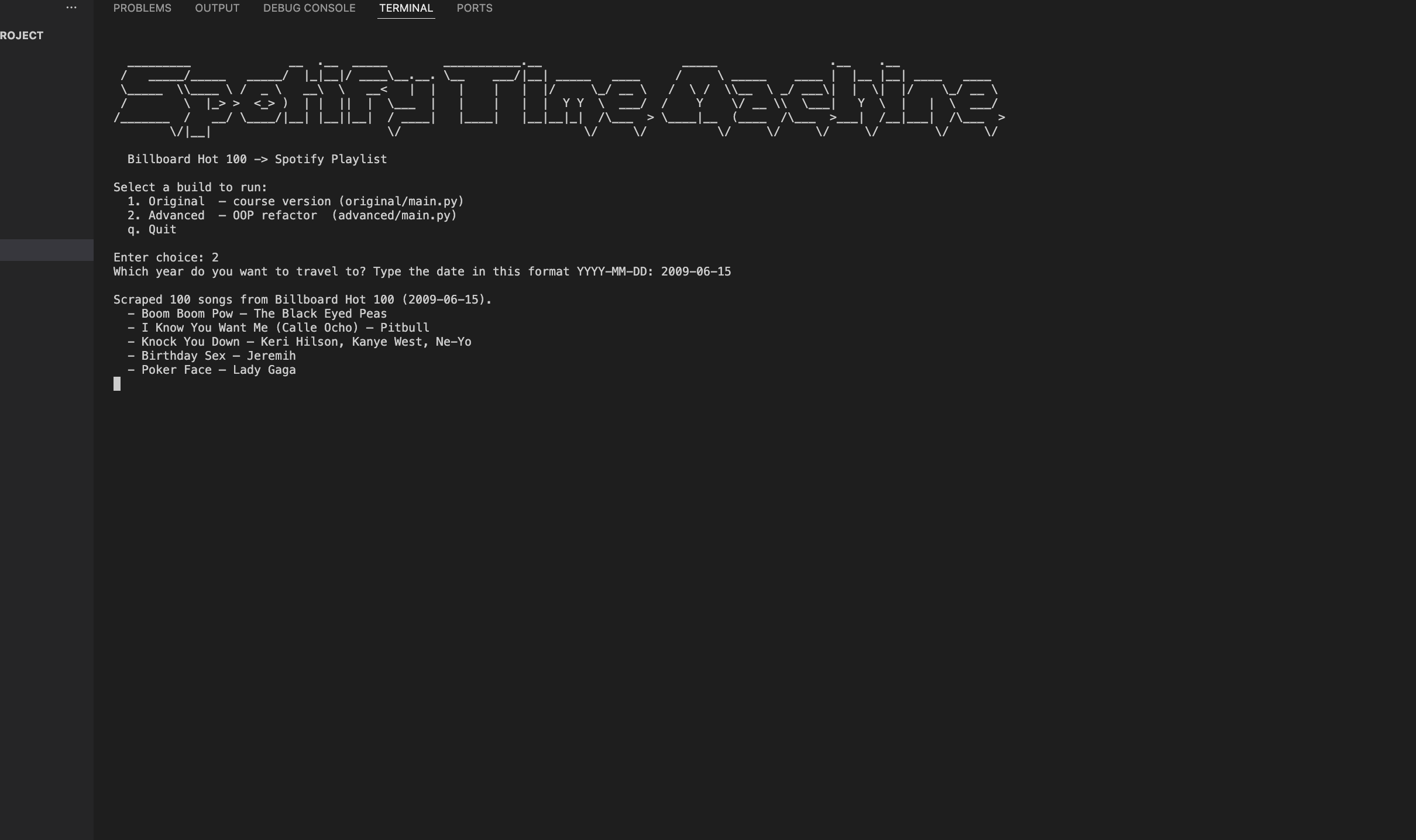
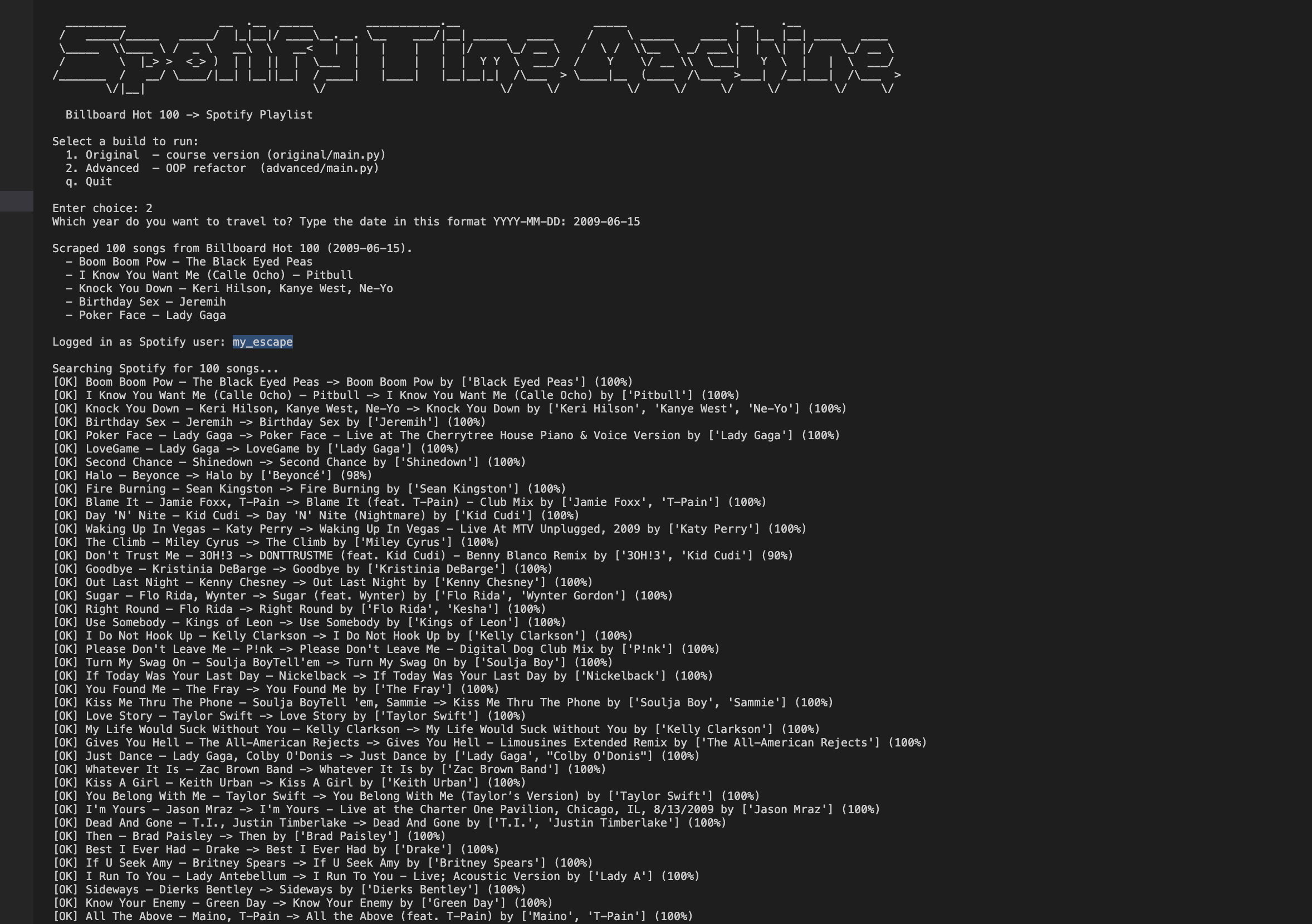
The tool scrapes billboard.com directly using requests and BeautifulSoup CSS selectors, then runs each (title, artist) pair through a multi-stage Spotify search pipeline via the spotipy library. Each search starts specific — track + artist + year — and falls back progressively to track + artist, then track only, and finally a broad title-only query with year-bonus scoring to avoid false positives. All fuzzy matching uses rapidfuzz.partial_ratio with a weighted composite score: title at 80% and artist at 20%, since title stability is higher across catalogue versions and reissues. The advanced build packages this into BillboardScraper and SpotifyClient classes with all constants centralised in config.py, keeping every threshold and URL in one place.
Challenges
Getting the fuzzy matching calibrated was the trickiest part — too strict and you reject valid songs with minor title differences, too loose and you accept wrong ones. Billboard has some genuinely edge-case entries: dual-title songs like "Candle In The Wind 1997/Something About The Way You Look Tonight" would never match as a full string, so the enhanced version splits on "/" and tries each part separately. Multi-artist tracks — "LL Cool J, Method Man, Redman, DMX, Canibus And Master P" — score poorly on artist comparison because Spotify may credit the same track differently, so the threshold is adaptively relaxed for three or more featured artists. The broad fallback query blends title score (70%) with a year-match bonus (30%) rather than artist comparison, which proved more reliable for catching stragglers without pulling in unrelated songs that share a common short title.
Results / Metrics
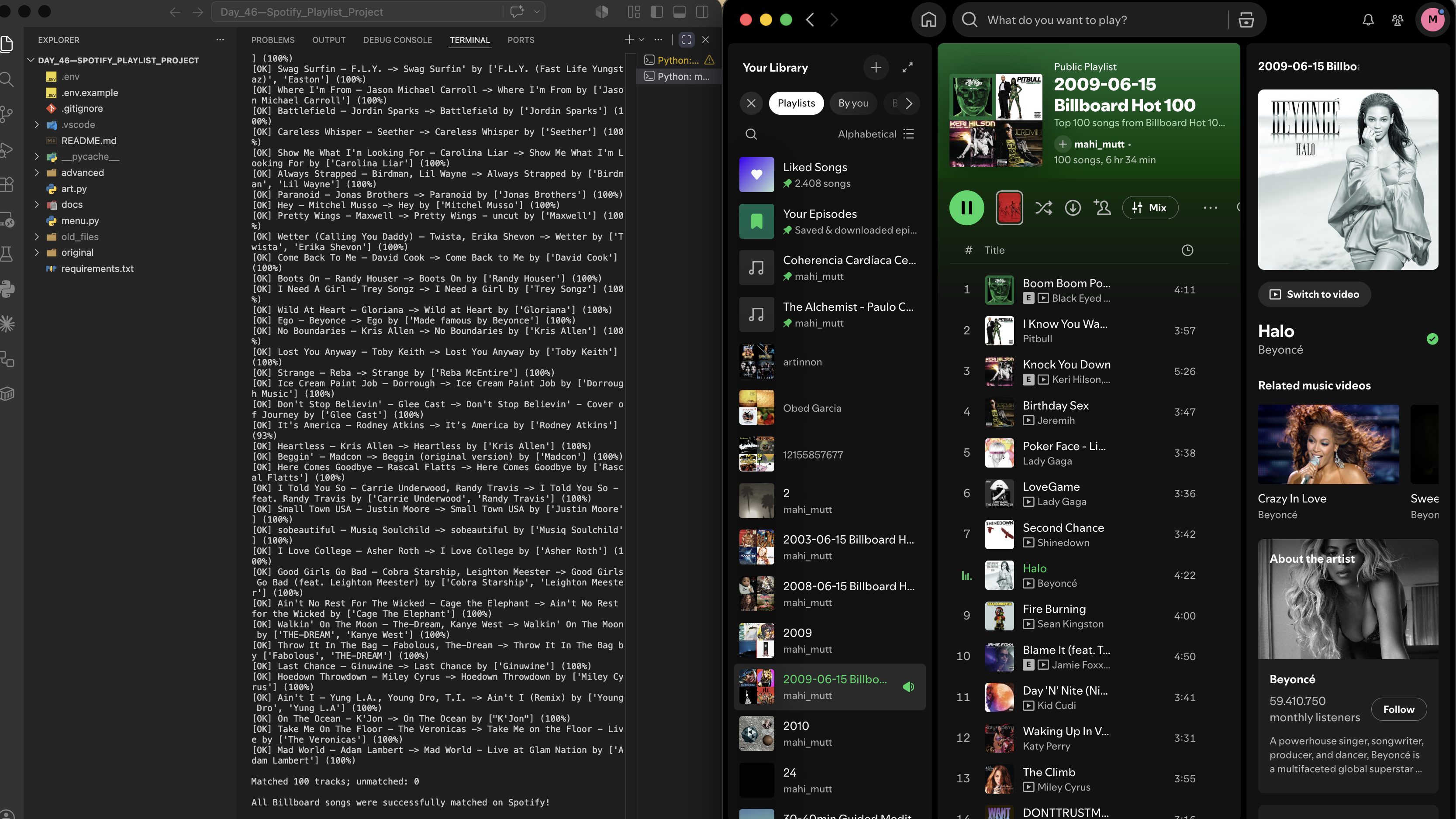
The tool reliably matches 95–97% of any given week's Hot 100 — the 1998-03-01 test run found 97 out of 100 songs, with the three unmatched being genuinely obscure catalogue gaps on Spotify's end rather than matching failures. The project gave me hands-on experience with OAuth 2.0 flows in practice, designing a fuzzy-matching pipeline with principled fallback logic, and refactoring a working procedural script into clean OOP modules without changing any behaviour. If I were building this again I'd add a local cache so repeated runs on the same date skip the 100 Spotify search calls, and I'd experiment with Spotify's audio features API to add decade-accurate mood filters on top of the chart data.
Screenshots
Click to enlarge.
Click to enlarge.